This is a start of a series of blog posts I am planning to do on the topic "Building your own PaaS using Apache Stratos (Incubator) [1] PaaS Framework".
PaaS, wondering what it is? It stands for Platform as a Service. It is the layer on top of the Infrastructure as a Service (IaaS) layer in the Cloud Computing Stack. Rackspace has published a white paper on the Cloud Computing Stack, and you may like to read it [2].
With the evolution of Cloud Computing technologies, people have realized the benefits that they could bring to their Organizations using Cloud technologies. Few years back they were happy to use an existing PaaS and develop/deliver their SaaS (Software as a Service) applications on top of it. But now, the industry has come to a state where they like to customize and build their own PaaS without being depended till the PaaS vendors deliver the customizations they need.
There arises a need of a framework where you have the freedom to customize and build the PaaS you wish. In this sense, having a pluggable, extensible and more importantly free and open source PaaS framework would be ideal. Hard to believe an existence of such framework? No worries, Apache Stratos (Incubator) is there for you!
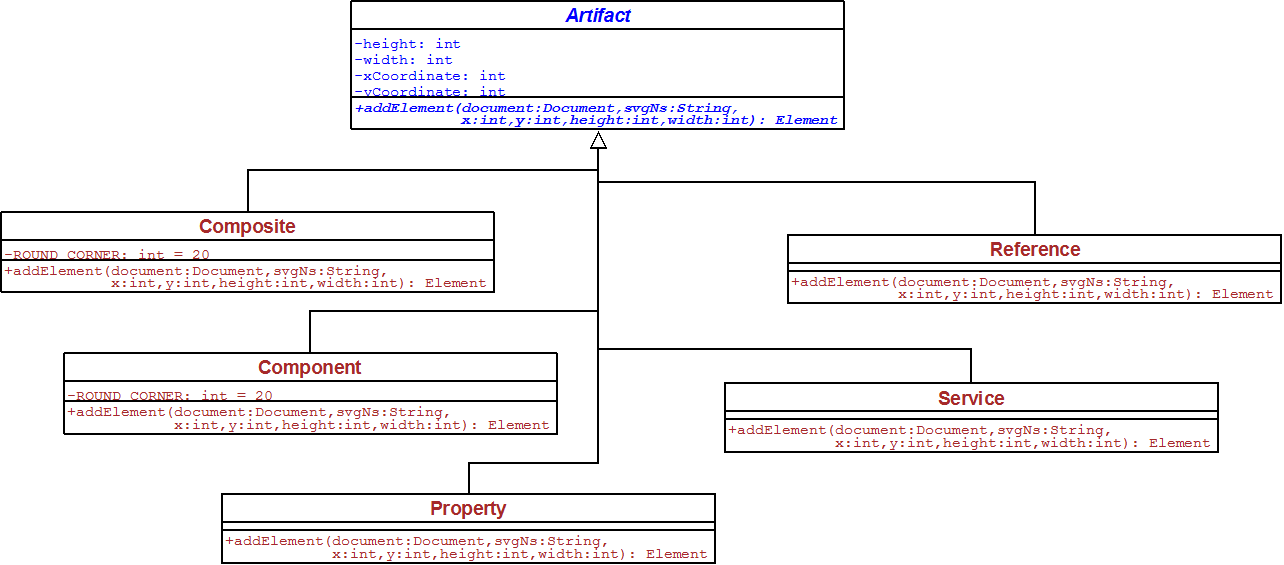
Before go into details on the topic I am gonna discuss, it is worth to understand how Apache Stratos looks like. Apache Stratos consists of set of core components and the diagram below depicts them.
Currently Apache Stratos internally uses 3 main communication protocols, namely AMQP, HTTP and Thrift.
AMQP protocol is mainly used to exchange topology information across core components. 'Topology' explains the run-time state of the PaaS at a given time such as existing services, service clusters, members etc.
HTTP protocol is used to perform SOAP service calls, among components.
Thrift protocol is used to publish various statistics to the Complex Event Processing Engine.
What does Apache Stratos (Incubator) core components capable of doing? Lakmal has explained this in [3].
In this first post of series of posts to come, I will roughly go through the major work-flows you need to do perform, in order to bring up your own PaaS, using Apache Stratos. Have a look at the below diagram;
As the sequence diagram explains, to build your own PaaS, in minimum, you need to follow the steps up to 'PaaS is ready!' state. Here, I am going to discuss the very first step you need to follow; that is 'Deploy Partitions'.
Let's understand the terminology first. What you deploy via a Partition is a reference to a place in an IaaS (eg: Amazon EC2/ Openstack etc.), which is capable of giving birth to a new instance (machine/node). Still not quite understood? Don't panic, let me explain via a sample configuration.
{
"id": "AWSEC2AsiaPacificPartition1",
"provider": "ec2",
"property": [
{
"name": "region",
"value": "ap-southeast-1"
},
{
"name": "zone",
"value": "ap-southeast-1a"
}
]
}
The above JSON defines a partition. Partition has a globally unique (among partitions) identifier ('id') and an essential element 'provider' which points to the corresponding IaaS provider type. This sample has two properties call 'region' and 'zone'. The properties you define here should be meaningful in the context of relevant provider. For an example, in Amazon EC2, there are regions and zones, hence you can define your preferred region and zone, for this partition. So, in a nut shell, what this partition references to is, ap-southeast-1a zone in ap-southeast-1 region of Amazon EC2. Similarly, if you take Openstack, they have regions and hosts.

Above sequence diagram explains the steps that get executed when you deploy a partition. You can either use Stratos Manager REST API or Apache Stratos CLI tool or Stratos Manager UI when deploying partitions. Partition deployment is successful only if the partitions are validated against their IaaS providers at Cloud Controller. Autoscaler is the place where these Partitions get persisted and it is responsible for selecting a Partition when it decides to start up a new instance.
Following is a sample CURL command to deploy partitions via REST API;
curl -X POST -H “Content-Type: application/json” -d @request -k -v -u admin:admin https://{SM_HOST}:{SM_PORT}/stratos/admin/policy/deployment/partition
@request should point to the partition json file. More information on the partition deployment can be found at [4].
That concludes the first post, await the second!
References:
[1]
http://stratos.incubator.apache.org/
[2]
http://www.rackspace.com/knowledge_center/whitepaper/understanding-the-cloud-computing-stack-saas-paas-iaas
[3]
http://lakmalsview.blogspot.com/2013/12/sneak-peek-into-apache-stratos.html
[4] https://cwiki.apache.org/confluence/display/STRATOS/4.0.0+Deploying+a+Partition